Compete Machine Learning Training Process
Image link: CENTRIC
The standard process of a model traning has listed in above image, and in this project, I will follow the process to build up the model for predicting the interest rate.
1. Check the data features and missing status
First step, we can first take a look into the data structures, and observe the data types in each columns.
After doing EDA, we need to take a look into the data missing status.
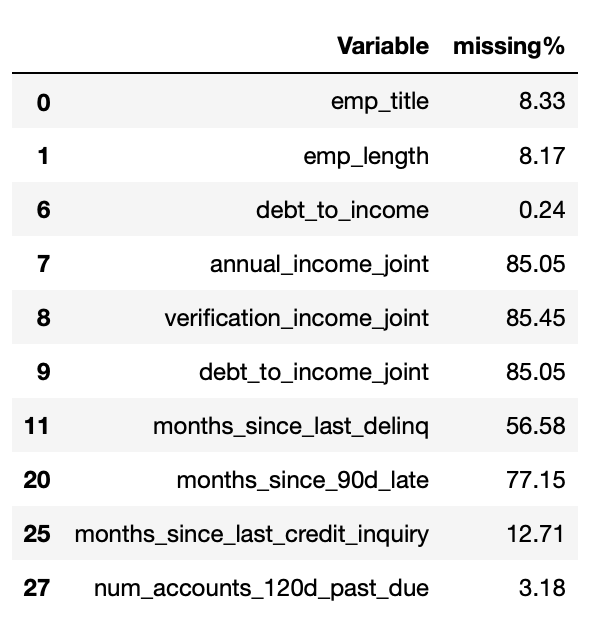
The features in the table are the features who include missing value. And we will drop the features who include more then 50% missing value.
For the "emp_title" and "emp_length", we will also drop them, as our observation, in the "emp_title" column, it includes too many titles and it would not be that valuable for us to keep it as our feature, and from our perspevtive, the "emp_length" is also not that meaningful in this dataset.
For "those two numerical columns "months_since_last_credit_inquiry" and "num_accounts_120d_past_due", we will use the mean of those columns to input the missing value.
For "debt_to_income", it is not reasonable for us to just input the mean, since this value may be highly correlation with other features, and also the missing values are not that many, so we decided to just drop the missing values.
Correlation plot
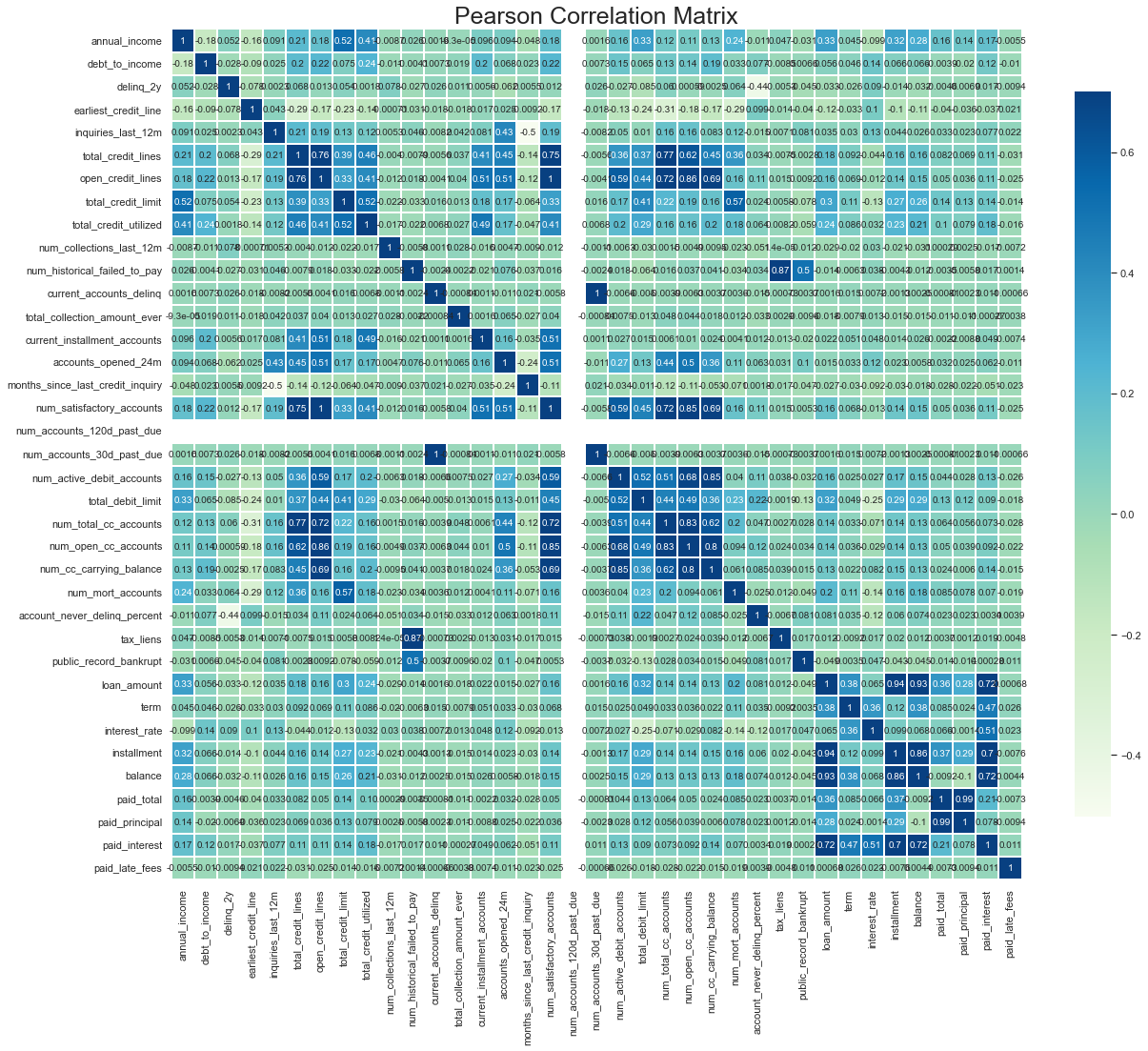
Create a correplation to observe the correlation between each features.
2. Data Preparation
a. Feature Encoding for categorical data
We need to do feature encoding for the categorical data, in this project I used the "One-hot encoding" technique to process the data, since I don't want the data has the ordinal effect.
b. Select the features and target value
In this project, since we are predicting the interst rate, so we will set the interest rate as our target value, and the rest of the columns as our features.
c. Split the data into Train and Test
In this step, we will split our dataset into training and testing dataset, and here I will split the data as 8:2.
3. Build the models and train
Since our target data is continuous data, I will select some regression model as our models to predict the interest rate.
A. Linear Regression
For selecting the regression model, I will always select Linear Regression as our baseline model to start the modeling process.

From the evaluation scores, we can see the linear regression is a great model to predict the interest rate, since it has a very high R square value and pretty low MAE.
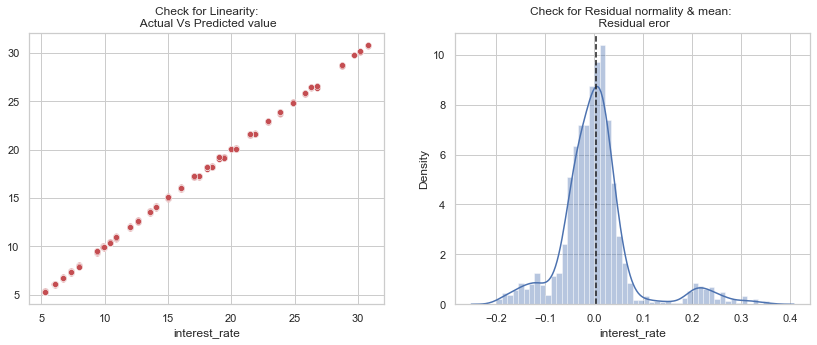
B. XGBoost Regression
As we all know that XGBoost performs pretty well in lots of Kaggle competetion, so I would like to also build up a XGB regression model.

From the evaluation scores, we can see the XGB also performs well in this case, but still can not beat our baseline model based on the R square value.
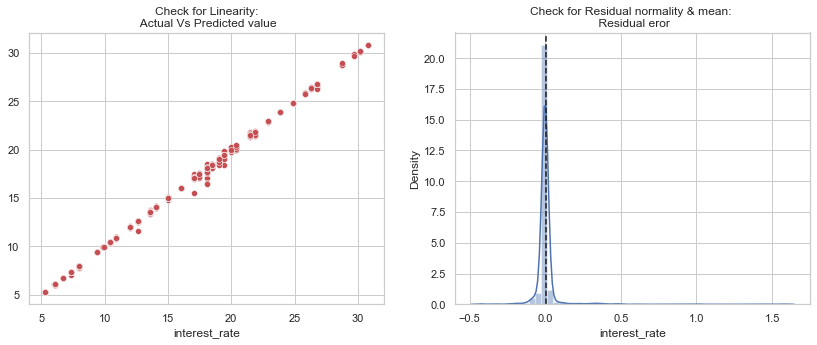
Conclusion
In this project, we can get pretty well result form both models, I think the features we used are all good predictor variables.
Both models can be utilized to predict the interest rate for future applicatnts.
Future Improvememt
In current model building process, I simply imput all processed features into the model, but in the future, if I have more time, I would like to do further Feature Engineering to process the features, decrease the number of features, and produce some useful features based on the current features. It might help us to train the model more quickly and easily.